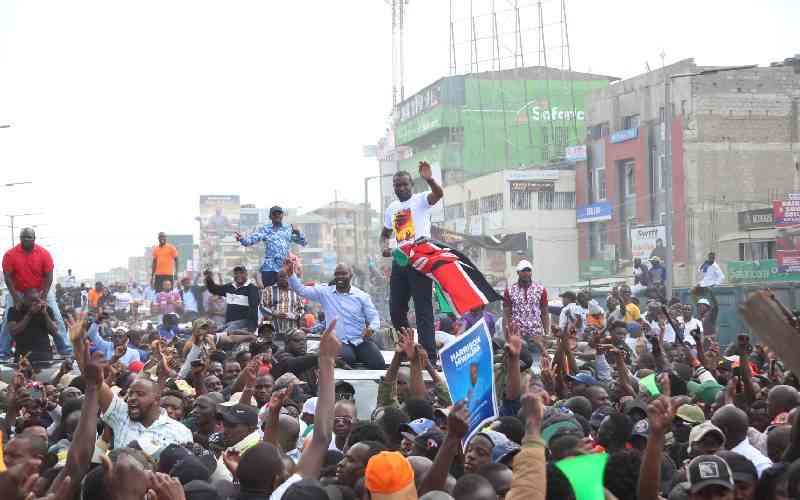×

The Standard e-Paper
Smart Minds Choose Us

For months, there has been unfettered and unified condemnation of opinion polls on the popularity of presidential candidates which has thrust local survey firms into the spotlight.
In what sounds like an oxymoron, both sides of the political divide have poured vitriol on recent opinion polls over their "inaccuracies" even as the formations needed reliable evidence-based data to inform campaigns.
Subscribe to our newsletter and stay updated on the latest developments and special offers!